

Agentic AI adaptation frameworks
Agentic AI adaptation frameworks are quickly becoming the cornerstone of next-generation intelligent systems. As hype builds around autonomous agents that can reason, plan, and act, expectations soar that these frameworks will unlock seamless tool use, complex planning, and memory-augmented capabilities. Yet the leap from impressive demos to reliable real-world performance remains steep, exposing gaps in robustness, scalability, and evaluation.
These agentic AI systems sit atop large language models, leveraging their vast knowledge while extending them with external tools and memory modules. In practice, orchestrating tool use, handling ambiguous queries, and maintaining coherent long-term plans demand sophisticated adaptation techniques. Researchers are therefore exploring four core paradigms-A1, A2, T1, and T2-to fine-tune agents and tools alike, balancing verifiable feedback with final-output signals.
While the promise is alluring-agents that can write code, discover scientific insights, or manage enterprise workflows-the reality often reveals brittle behavior, missed tool calls, or forgotten context. This introduction sets the stage for a deep dive into why high hopes meet hard limits, and how the emerging adaptation frameworks aim to bridge that gap, delivering more dependable, scalable, and trustworthy agentic AI.
Understanding Agentic AI adaptation frameworks
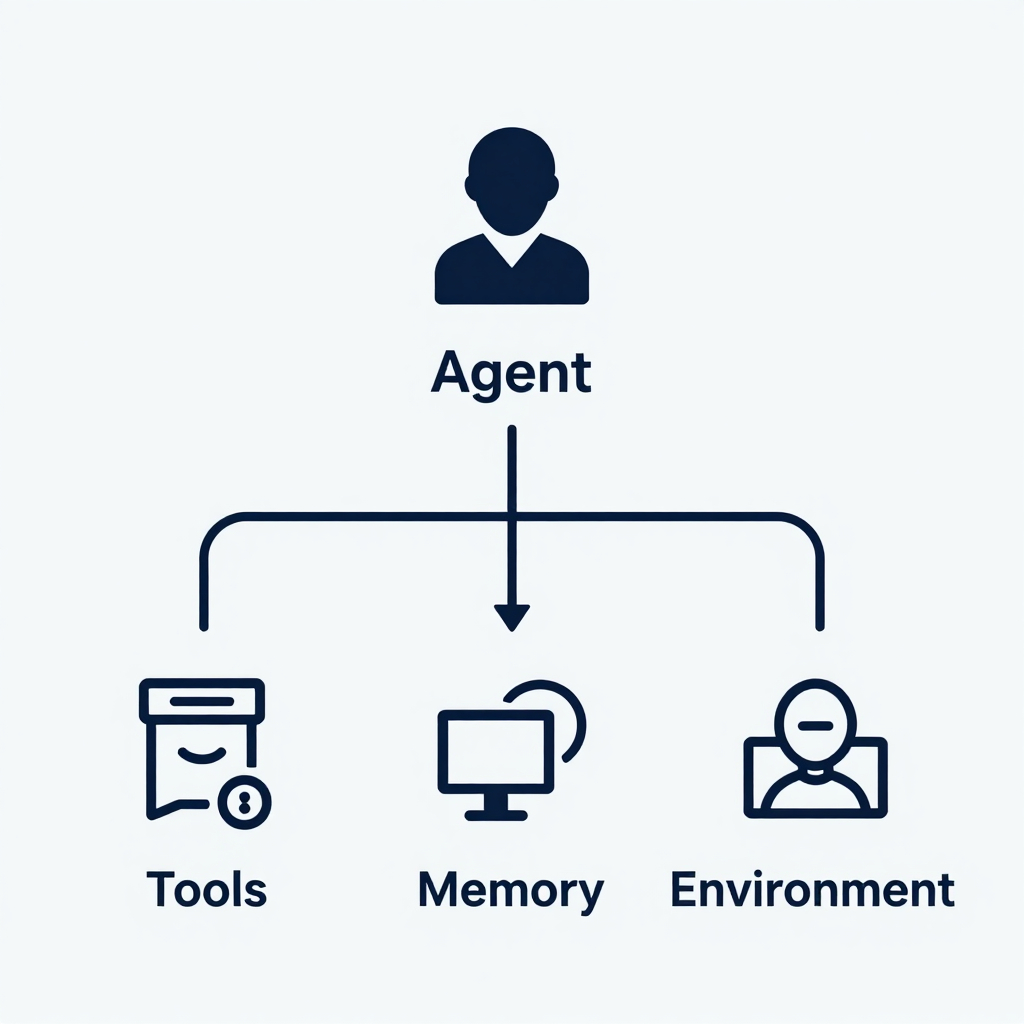
Agentic AI systems sit on top of large language models and connect to tools, memory, and external environments. The core architecture consists of four interacting parts:
- Agent – the reasoning engine that generates actions, often using a planning module and Chain-of-Thought prompting.
- Tools – APIs, simulators, or retrievers that the agent can call; examples include searchers like DeepRetrieval or the s3 7-billion-parameter searcher.
- Memory – a long-term store that preserves context across episodes; treated as a special case of tool adaptation.
- Environment – the external world that provides observations and receives the agent’s outputs.
These components enable retrieval-augmented generation (RAG) where the agent retrieves relevant information before producing a response.
The research paper “Adaptation of Agentic AI”, a collaboration among Stanford, Harvard, UC Berkeley, and Caltech, defines four adaptation paradigms by crossing two binary choices: target (agent vs. tool) and supervision signal (tool execution vs. final output).
- A1 (agent-agnostic tool adaptation) – adapts the agent directly from verifiable tool feedback. Methods such as Toolformer, ToolAlpaca, Gorilla, and DeepRetrieval belong here.
- A2 (agent-supervised tool adaptation) – optimizes the agent using final-output signals, requiring extra supervision of tool calls or sparse rewards.
- T1 (tool-centric adaptation) – adapts tools independently of any specific agent, allowing reuse of trained searchers across agents.
- T2 (tool adaptation under a frozen agent) – adapts tools while keeping the main agent fixed; examples include the s3 searcher and the AgentFlow planner built on frozen Qwen2.5 modules. Long-term memory adaptation follows the same T2 pattern.
Practical systems combine infrequent A1/A2 updates on a strong base model with frequent T1/T2 refinements of retrievers, simulators, and memory, delivering robustness and scalability.
| Paradigm | Target (Agent / Tool) | Supervision Signal | Example Methods | Key Benefit |
|---|---|---|---|---|
| A1 | Agent | Verifiable tool execution feedback | Toolformer, ToolAlpaca, Gorilla, DeepRetrieval | Direct, reliable improvement from concrete tool outcomes |
| A2 | Agent | Final-output signal (sparse reward) | Output-supervised fine-tuning, RLHF-style reward models | Aligns agent with end-task success despite limited tool signals |
| T1 | Tool | Verifiable tool execution feedback (agent-agnostic) | DeepRetrieval searcher, generic tool adapters | Enables reusable tool models across multiple agents |
| T2 | Tool | Final-output-driven adaptation under frozen agent | s3 7-B searcher, AgentFlow planner, memory store learning | Specializes tool behavior while keeping the main agent stable |
Key Techniques and Notable Implementations
Agentic AI builds on large language models and connects them to external tools, memory stores, and retrieval modules. Recent research identifies several A1 and T2 methods that learn directly from tool feedback or adapt frozen components for new tasks. Below is a concise overview of the most cited techniques.
-
Toolformer – An A1 approach that fine-tunes the base language model to invoke tools when a low-confidence signal appears. It leverages Low Rank Adaptation to keep parameter updates lightweight. Pros: fast adaptation, minimal compute overhead. Cons: requires a curated dataset of tool-call annotations. The paper notes “A1, learning from verifiable tool feedback” and lists Toolformer among the primary A1 methods【facts】.
-
ToolAlpaca – Extends the Alpaca instruction-tuning recipe with tool-use examples, enabling the model to generate syntactically correct API calls. Pros: improves zero-shot tool accuracy, works well with small instruction sets. Cons: still dependent on manual prompt engineering for each new tool. It is grouped with Toolformer and Gorilla as A1 techniques【facts】.
-
Gorilla – Trains a language model to follow tool-use policies derived from human demonstrations. The method incorporates Proximal Policy Optimization to balance exploration and adherence to correct tool semantics. Pros: strong alignment with human intent, robust across diverse APIs. Cons: PPO training can be unstable without careful KL-regularization. The authors cite it as an A1 method that learns from verifiable feedback【facts】.
-
DeepRetrieval – Frames query reformulation as a Markov decision process and optimizes it with KL-regularized Proximal Policy Optimization. This T1 technique acts as a searcher that can be swapped across agents. Pros: high retrieval recall, adaptable to new domains. Cons: training cost grows with corpus size. The fact sheet states “DeepRetrieval frames query reformulation as a Markov decision process and is trained with KL-regularized Proximal Policy Optimization”【facts】.
-
AgentFlow – A T2 planner built on frozen Qwen2.5 modules that orchestrates tool sequences without updating the underlying language model. Pros: rapid deployment, reuses existing large models. Cons: limited by the expressive power of the frozen backbone. Mentioned as an example of T2 adaptation where the tool component is learned while the agent stays frozen【facts】.
-
s3 searcher – A 7-billion-parameter retrieval model that serves as a T2 component for large-scale vector search. It learns a specialized index while leaving the main agent untouched. Pros: scalable to billions of documents, low latency. Cons: requires extensive pre-training data and hardware. The article describes it as “the s3 7-billion-parameter searcher … example of T2 adaptation”【facts】.
These techniques illustrate how Low Rank Adaptation, Proximal Policy Optimization, and Retrieval-Augmented Generation (RAG) intertwine to push agentic AI toward practical, real-world performance.
CONCLUSION
The survey of Agentic AI adaptation frameworks reveals a coherent taxonomy that separates adaptation at the agent level (A1, A2) from adaptation at the tool or memory level (T1, T2). By crossing the dimensions of target (agent vs. tool) and supervision signal (tool execution vs. final output), the four paradigms clarify why current systems excel in controlled demos yet stumble when deployed at scale. In practice, A1 methods such as Toolformer and DeepRetrieval provide reliable, verifiable feedback but demand costly annotation pipelines, while A2 approaches leverage final-output rewards but suffer from sparse signal and delayed credit assignment. Conversely, T1 and T2 adaptations enable rapid re-use of retrievers, planners, or long-term memory modules without retraining the core language model, offering a pragmatic path to robustness and scalability.
Nevertheless, several limits persist. Tool-feedback loops remain brittle when external APIs change, memory stores can drift without continual alignment, and evaluation metrics like nDCG or recall capture only narrow aspects of real-world utility. Moreover, the heavy computational budget of KL-regularized PPO or DPO constrains widespread adoption outside well-funded labs.
Future research should therefore explore hybrid schemes that combine occasional A1/A2 fine-tuning with continuous T1/T2 updates, develop richer self-supervised signals for tool use, and design standardized benchmarks that reflect end-to-end task success. Advances in low-rank adaptation and group-relative policy optimization also promise to lower the cost barrier for iterative improvement.
SSL Labs is an innovative Hong Kong-based startup specializing in cutting-edge AI solutions. We build custom AI applications, end-to-end machine-learning pipelines, and advanced NLP and computer-vision tools, all under a strict ethical AI framework that prioritizes transparency, bias mitigation, and privacy. Our portfolio includes AI Application Development, ML Solutions, Predictive Analytics, and AI Research & Prototyping, delivered securely on cloud platforms or client infrastructure.
Frequently Asked Questions (FAQs)
Q: What is an Agentic AI adaptation framework?
A: It is a systematic approach for updating agents or their tools-such as retrievers or memory modules-so they work better with large language models and external environments.
Q: How do the four paradigms (A1, A2, T1, T2) differ?
A: A1 and A2 adapt the agent itself (using tool feedback or final-output signals), while T1 and T2 adapt the tools (with or without a frozen agent).
Q: When should I choose tool adaptation over agent adaptation?
A: Use tool adaptation when you need reusable components across agents or want frequent updates without retraining the whole model.
Q: What practical steps are needed for real-world deployment?
A: Combine occasional A1/A2 updates on a strong base model with regular T1/T2 refinements, and monitor memory and retrieval metrics like nDCG and recall.
Q: How can I monitor and improve tool execution signals?
A: Log tool call outcomes, compare them against expected results, and feed the discrepancies back into the adaptation loop for continuous learning.