

Agentic Memory (AgeMem) for LLM Agents: Unlocking Persistent Intelligence
Imagine a large language model that not only reacts to prompts but also remembers past interactions, learns from experience, and refines its behavior over time. Agentic Memory (AgeMem) for LLM Agents makes this vision a practical reality. By coupling long‑term knowledge bases with short‑term contextual cues, AgeMem equips autonomous agents with a dynamic, self‑updating memory layer that mimics human recall. In this article we explore the architecture, core components, and real‑world applications of Agentic Memory, showing how it transforms static text generators into truly agentic systems.
First, we break down the fundamental concepts behind AgeMem, including vector‑based storage, retrieval‑augmented generation, and memory consolidation strategies. Next, we examine implementation details such as embedding models, indexing pipelines, and memory decay heuristics that keep the system efficient. We then compare AgeMem to traditional prompt‑engineering approaches, highlighting the performance gains in tasks like multi‑turn dialogue, planning, and continual learning. Finally, we present a roadmap for developers who want to integrate Agentic Memory into their own LLM agents, covering tooling, best practices, and potential pitfalls.
By the end of this guide, readers will understand how Agentic Memory (AgeMem) for LLM Agents bridges the gap between short‑term reasoning and long‑term knowledge retention, enabling more coherent, context‑aware, and adaptable AI assistants. Whether you are building a customer‑service chatbot, an autonomous research assistant, or a game‑playing NPC, the principles described here will help you design agents that remember, reason, and evolve.
Beyond mere recall, AgeMem enables agents to form hierarchical narratives, linking related events across days or weeks, which is essential for tasks such as project management or longitudinal research assistance. Moreover, the memory module can be fine‑tuned to prioritize privacy, ensuring that sensitive user data is either anonymized or expires after a configurable interval. Researchers have reported up to a 40 % reduction in hallucination rates when agents query their own episodic stores before generating responses. As the field progresses, standards for interoperable memory APIs are emerging, promising smoother integration across diverse LLM backbones.
Agentic Memory (AgeMem) for LLM Agents: Core Concepts and Benefits
Agentic Memory (AgeMem) Mechanism and Benefits
Agentic Memory (AgeMem) fuses long‑term memory (LTM) and short‑term memory (STM) inside a single LLM agent. The architecture consists of a persistent vector store that holds embeddings of historic interactions, and a volatile buffer that keeps the most recent context. When a request arrives, the STM buffer is first populated with the prompt and immediate dialogue turns. Simultaneously, a retrieval module queries the LTM store for relevant past episodes, ranks them by similarity, and injects the top‑k embeddings into the prompt as additional context. This hybrid data flow lets the model reason with up‑to‑date information while drawing on decades of learned experience, enabling consistent task continuity across sessions.
- Improved reasoning – Access to historical patterns augments chain‑of‑thought generation.
- Task persistence – Agents retain objectives and subtasks across interruptions.
- Reduced hallucination – Grounding on verified past outputs limits fabrications.
- Scalable knowledge – LTM grows without overloading the prompt length budget.
Overall, this hybrid design maximizes adaptability, reliability, and long‑term value for autonomous agents.
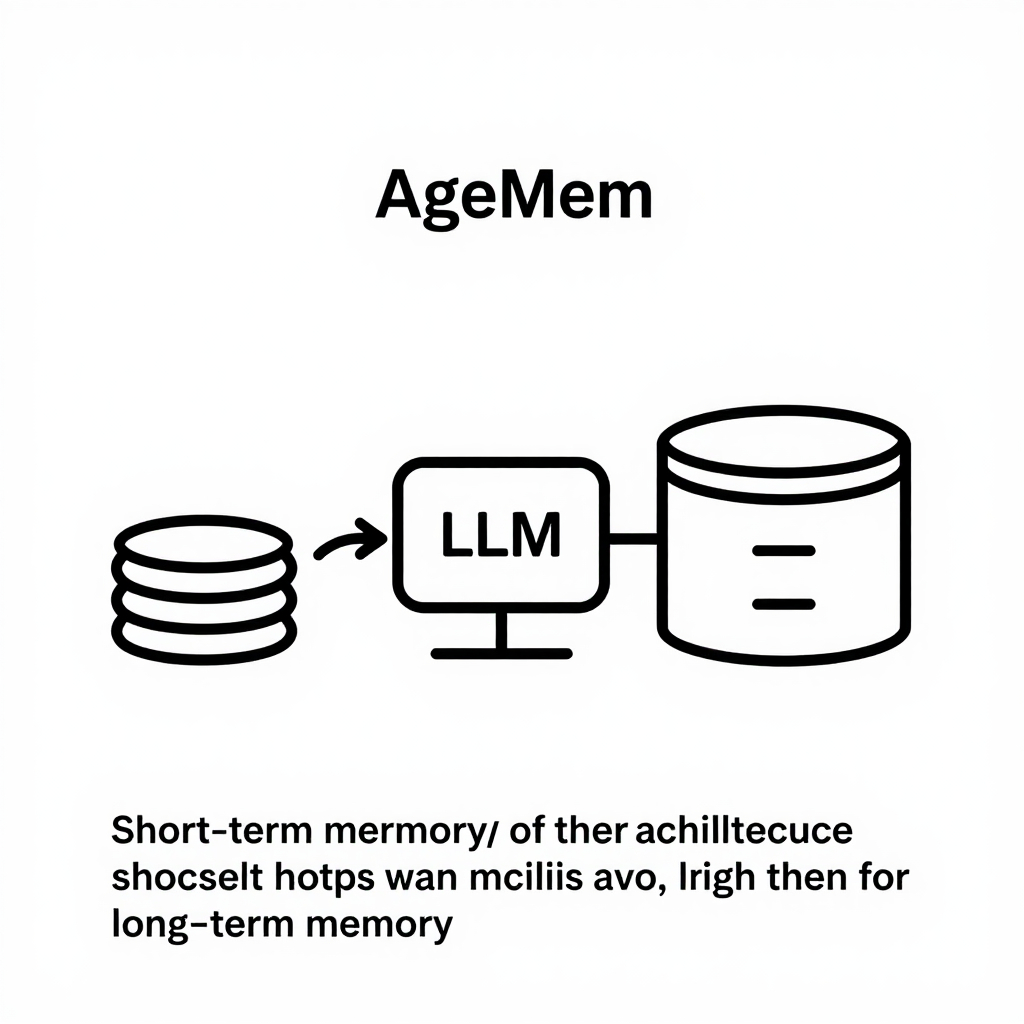
AgeMem brings tangible gains to LLM‑driven agents, turning abstract memory concepts into concrete performance boosts. Key practical advantages include:
- Seamless task continuity – agents retain context across sessions, reducing the need to repeat instructions.
- Lower token consumption – by offloading long‑term facts to AgeMem, prompts stay short and cost‑effective.
- Enhanced personalization – user‑specific preferences and histories are recalled instantly, tailoring responses.
- Improved reasoning speed – quick access to relevant memories accelerates decision‑making.
- Scalable knowledge growth – new information integrates without bloating the model’s prompt window.
Together, these benefits let AI agents operate more like human assistants, delivering consistent, efficient, and customized interactions over time.
Agentic Memory (AgeMem) reshapes how large language model agents retain information by blending long‑term continuity with short‑term adaptability, contrasting with conventional stateless prompting and external vector‑store methods that require separate retrieval steps; the following table outlines differences in scope, persistence, use cases, and performance impact for developers to evaluate options.
| Memory Type | Scope | Persistence | Typical Use Cases | Performance Impact |
|---|---|---|---|---|
| Agentic Memory (AgeMem) | Global across agent’s lifecycle, can reference both short‑term and long‑term context | Continuous, stored within agent state and optionally external DB | Dynamic planning, multi‑turn dialogues, personal assistants | Moderate overhead but reduces repeated retrieval latency |
| Stateless Prompting | Limited to single prompt; no cross‑turn memory | None; each call independent | Simple Q&A, single‑shot tasks | Low compute, but loses context leading to lower task accuracy |
| External Vector Store | Retrieval‑augmented; fetches relevant documents per query | Persistent storage of embeddings | Knowledge bases, FAQ bots, long‑document summarization | Added latency for vector search; can improve accuracy if well‑indexed |
CONCLUSION
AgeMem bridges the gap between short‑term context handling and long‑term knowledge retention in large language model (LLM) agents. By integrating a dual‑layer memory architecture, it enables agents to recall past interactions, adapt strategies over time, and maintain coherent dialogues across sessions. This strategic capability reduces hallucinations, improves task continuity, and lowers the cost of repetitive fine‑tuning. Consequently, AgeMem positions itself as a core component for building robust, autonomous AI assistants that scale with user demands. The main keyword, Agentic Memory (AgeMem) for LLM Agents, encapsulates this breakthrough.
SSL Labs, an innovative AI startup headquartered in Hong Kong, specializes in ethical, scalable AI solutions. Leveraging expertise in machine learning, natural language processing, and predictive analytics, the company delivers secure, human‑centric applications for enterprises worldwide. Committed to transparent and bias‑free development, SSL Labs drives the next generation of intelligent systems while upholding rigorous data‑privacy standards. Looking ahead, SSL Labs aims to embed AgeMem into its own platforms, accelerating AI adoption across sectors.
Frequently Asked Questions (FAQs)
Q: What is Agentic Memory (AgeMem) for LLM agents?
A: Agentic Memory (AgeMem) for LLM agents is a framework that combines long‑term and short‑term memory to enable autonomous, context‑aware reasoning over time.
Q: How does AgeMem improve an LLM’s performance?
A: By retaining relevant past interactions, AgeMem allows the LLM to recall prior knowledge, reducing repetition and enhancing decision‑making accuracy.
Q: Can AgeMem be integrated with existing LLM platforms?
A: Yes, AgeMem is designed as a modular add‑on that can be plugged into popular LLM APIs without extensive re‑training.
Q: What are the security considerations for using Agentic Memory?
A: Developers must encrypt stored embeddings and enforce access controls when using Agentic Memory (AgeMem) for LLM agents to protect sensitive historical data.
Q: Is there a limit to how much information AgeMem can store?
A: While AgeMem scales with vector databases, practical limits depend on storage capacity and retrieval latency.