

Production-Grade Agent Architecture: Inside the Agentic AI Revolution
The era of agentic AI is exploding, and enterprises are racing to deploy intelligent agents that can act autonomously. Because these systems now handle critical business processes, understanding Production-Grade Agent Architecture is no longer optional-it’s essential for success.
In this guide we break down the seven foundational pillars that separate experimental prototypes from reliable, scalable agents. You will learn how to design robust communication layers, implement secure data pipelines, enforce observability, and adopt continuous deployment practices that keep agents performant and trustworthy.
However, the promise of agentic AI comes with operational risks. Therefore, we emphasize best-practice safeguards-such as rigorous testing, version control, and monitoring-that prevent costly failures and ensure compliance. By the end of the article, you’ll have a clear roadmap to build production-grade agents that deliver real value while minimizing danger.
Key Aspects of Production-Grade Agent Architecture
| Pillar # | Pillar Name | Core Function | Key Considerations for Production |
|---|---|---|---|
| 1 | Observability | Track metrics, logs, traces | Real-time dashboards, alert thresholds, data retention policies |
| 2 | Scalability | Handle load growth | Auto-scaling rules, resource budgeting, latency budgets |
| 3 | Security | Protect data and actions | Authentication, encryption, threat monitoring |
| 4 | Robustness | Ensure reliable behavior | Failover mechanisms, circuit breakers, graceful degradation |
| 5 | Extensibility | Add new capabilities | Plug-in architecture, versioned APIs, backward compatibility |
| 6 | Governance | Enforce policies and compliance | Auditing, model provenance, usage quotas |
| 7 | Performance | Optimize speed and cost | Profiling, caching strategies, cost-benefit analysis |
Robust Perception Layer in Production-Grade Agent Architecture
The perception layer converts raw sensor streams into structured signals that downstream modules can trust. It typically combines computer-vision models, audio processing pipelines, and telemetry parsers.
- Multi-modal fusion: Aligns video, LiDAR, and text using time-stamp synchronization and coordinate transforms.
- Data validation: Applies sanity checks (e.g., range limits, checksum verification) to discard corrupt frames before inference.
- Edge preprocessing: Executes lightweight CNNs or DSP filters on-device to reduce bandwidth and latency.
Common pitfalls
- Over-reliance on a single sensor leads to brittle behavior when that modality fails.
- Ignoring drift in calibration causes systematic errors that propagate to the reasoning engine.
Real-world example – Autonomous delivery robots from Company X use a redundant perception stack that fuses 360° lidar, stereo cameras, and ultrasonic sensors. When a camera is blinded by glare, the lidar data seamlessly fills the gap, keeping navigation stable.
Scalable Reasoning Engine in Production-Grade Agent Architecture
The reasoning engine turns perceptual inputs into actionable plans while respecting performance and cost constraints. It orchestrates symbolic planners, reinforcement-learning policies, and rule-based validators.
- Hierarchical task decomposition: Breaks high-level goals into sub-tasks that can be executed in parallel across compute nodes.
- Probabilistic inference: Uses Bayesian networks or particle filters to handle uncertainty from the perception layer.
- Dynamic resource allocation: Scales GPU pods up or down based on request volume, preventing bottlenecks during peak loads.
Common pitfalls
- Tight coupling of policy networks with specific hardware makes scaling across cloud providers difficult.
- Insufficient logging of decision paths hampers root-cause analysis after failures.
Real-world example – The virtual assistant platform at Company Y runs a micro-service reasoning mesh. When user intent spikes during a product launch, the system automatically spawns additional inference containers, maintaining sub-second response times without manual intervention.
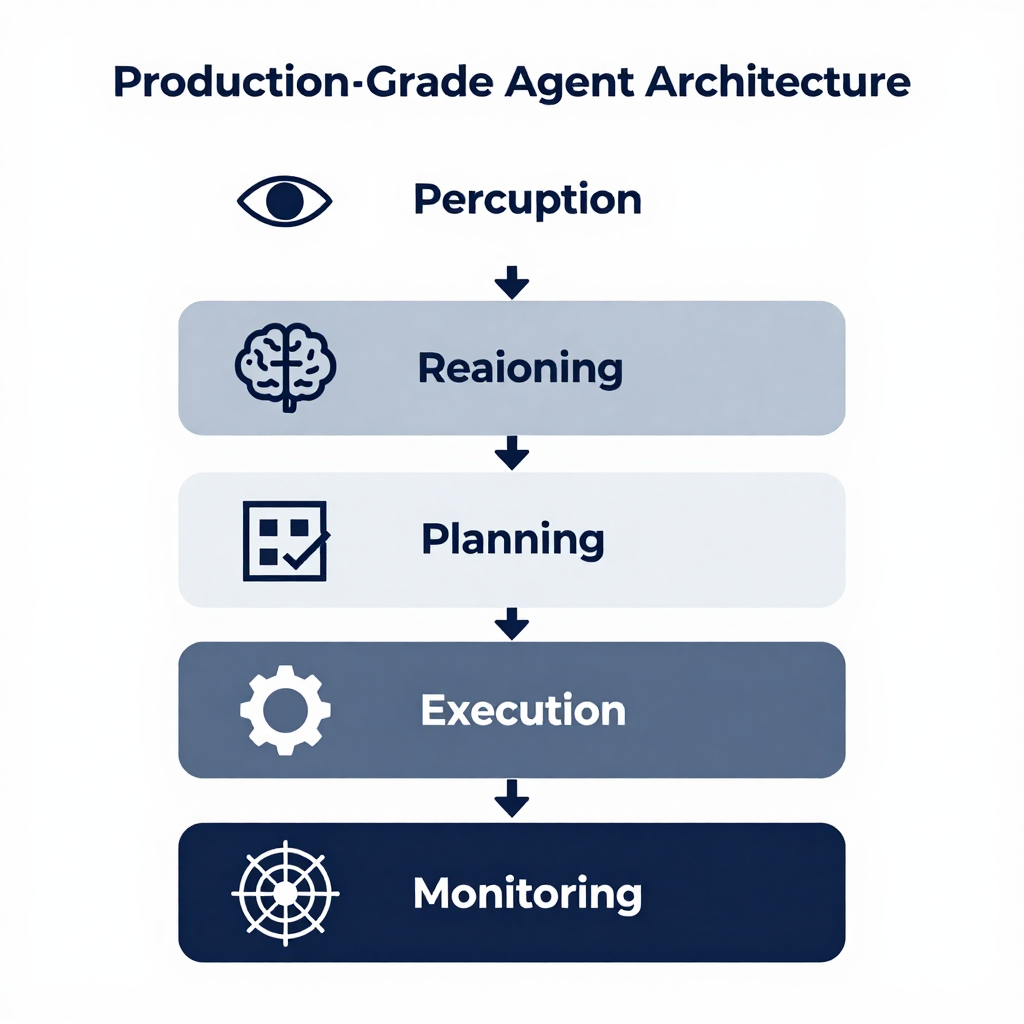
Implementing Production-Grade Agent Architecture Safely
Deploying agents at scale demands more than just code; it requires disciplined operations that keep systems reliable, secure, and trustworthy. Below are practical best-practice recommendations to build a production-grade agent architecture safely.
1. Monitoring & Observability
- Use centralized metrics (CPU, latency, error rates) and set alerts with thresholds that reflect SLA.
- Enable distributed tracing to pinpoint bottlenecks across micro-agents.
- Regularly review dashboards and automate anomaly detection to catch drift early.
2. Structured Logging
- Emit logs in JSON format with consistent fields (timestamp, agent ID, severity, context).
- Centralize logs in a secure log-aggregation service and retain them per compliance requirements.
- Mask or redact sensitive data before logging to prevent leakage.
3. Security Hardening
- Apply the principle of least privilege to API keys, tokens, and container capabilities.
- Enforce TLS for all inter-agent communication and rotate certificates regularly.
- Run agents inside sandboxed containers or VMs and keep runtime dependencies patched.
4. Version Control & CI/CD
- Store all agent code, configuration, and model artifacts in a Git repository.
- Tag releases with semantic versioning and maintain a changelog that records breaking changes.
- Automate builds, security scans, and deployment through a CI pipeline that requires peer review.
5. Testing Pipelines
- Implement unit tests for core logic, integration tests for API contracts, and end-to-end simulations of agent workflows.
- Include performance regression tests to verify latency and resource usage under load.
- Run ethical validation tests that check for bias, privacy violations, and unintended behavior before each release.
6. Ethical Governance
- Define clear usage policies and embed consent checks where agents handle personal data.
- Conduct regular audits of model outputs for fairness and transparency.
- Provide a rollback mechanism to suspend or revert agents that exhibit harmful actions.
Treat each recommendation as a mandatory checkpoint; overlooking any can expose your agents to downtime, data breaches, or regulatory penalties.
CONCLUSION
The seven pillars-data pipeline integrity, scalable model serving, comprehensive observability, rigorous security and compliance, modular orchestration, continuous learning, and governance with ethical AI-form the backbone of a resilient Production-Grade Agent Architecture. By weaving these components together, organizations can ensure agents remain reliable, secure, and adaptable as workloads grow. Ignoring any pillar risks downtime, bias, or costly breaches, underscoring why a solid architecture is non-negotiable for real-world deployments.
We encourage you to adopt the best-practice checklist outlined above, embed monitoring from day one, and iterate continuously to keep your agents production-ready. Adopt a Production-Grade Agent Architecture today to future-proof your AI initiatives.
About SSL Labs
SSL Labs is an innovative Hong-Kong-based startup that builds cutting-edge AI solutions across machine learning, NLP, computer vision, predictive analytics, and automation. The company champions ethical AI-ensuring transparency, bias mitigation, and privacy compliance-while delivering scalable, secure applications for enterprises. With a track record of boosting client revenue by up to 30%, SSL Labs offers custom AI development, end-to-end ML pipelines, and consulting services that empower businesses to deploy production-grade agent solutions with confidence.
Frequently Asked Questions
-
Q: What is Production-Grade Agent Architecture?
A: It is a blueprint that combines modular components, robust APIs, observability, fault tolerance, and secure data pipelines so AI agents can run reliably at scale in production environments. -
Q: Why is observability crucial for production-grade agents?
A: Observability provides real-time metrics, logs, and traces, allowing teams to detect anomalies, diagnose issues quickly, and maintain high availability without disrupting service. -
Q: How does security integrate into agent design?
A: Security is built in through authentication, encrypted communication, role-based access controls, and regular vulnerability scans, ensuring that agents handle data safely and comply with regulations. -
Q: What deployment strategies support continuous improvement?
A: Blue-green deployments, canary releases, and automated rollback mechanisms let developers update agent models and services without downtime, fostering rapid iteration while preserving stability. -
Q: Which monitoring tools are recommended for agent ecosystems?
A: Popular choices include Prometheus for metrics, Grafana for dashboards, OpenTelemetry for tracing, and centralized log aggregators like ELK Stack, all of which integrate smoothly with production pipelines.